I have data from the STOKES High Performance Compute Cluster which definitively shows that kernel versions prior to 2.6.24 can suffer significant performance degradation due to memory fragmentation. I noticed the problem on servers running Red Hat Enterprise Linux (RHEL) 5.4 with kernel version 2.6.18-164.el5. This post will document my findings. The graphs were taken from our Ganglia monitoring system.
This node has 24GB of RAM. As long as processes do not request more than 23GB of RAM, the node operates normally. Processes can use 23GB of RAM all day long:

Things started going wrong when more than 24GB of RAM was requested and the node started to thrash. In the following graph, a process requested 28GB of RAM and caused a small amount of swapping. After that, the node was still able to allocate 23GB of RAM. I then requested 32GB of RAM, which caused the node to swap and thrash. Only one CPU core was busy, and it was 100% allocated to system processes. Note how long it takes the node to allocate the memory-there is no processing going on here, so the time required to allocate 32GB is caused only by the swapping. I killed the process after about 15 minutes; it was never able to allocate 32GB of RAM:
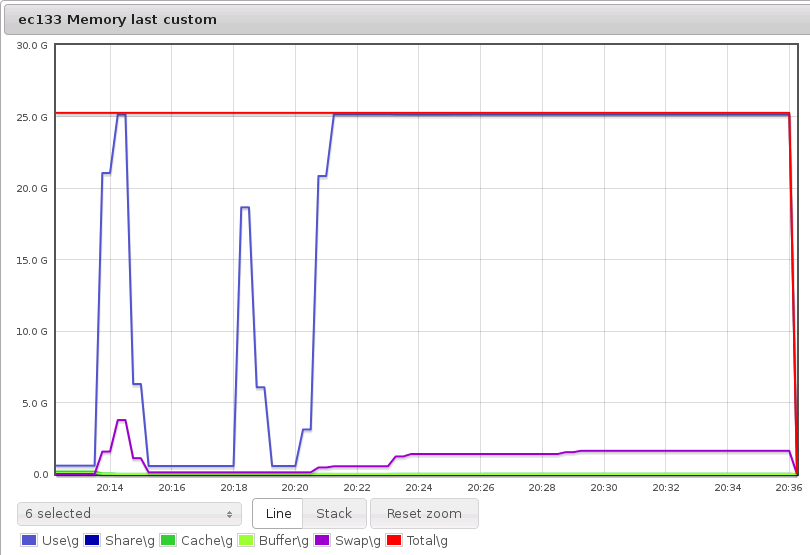
Once the node has returned from its “thrashing” state, it is unable to allocate blocks of memory. The following graph includes the data from the previous graph, showing the attempt to allocate 32GB of RAM. I then requested 23GB of RAM, and the node again entered the thrashing state, even though the node was previously able to allocate 23GB:
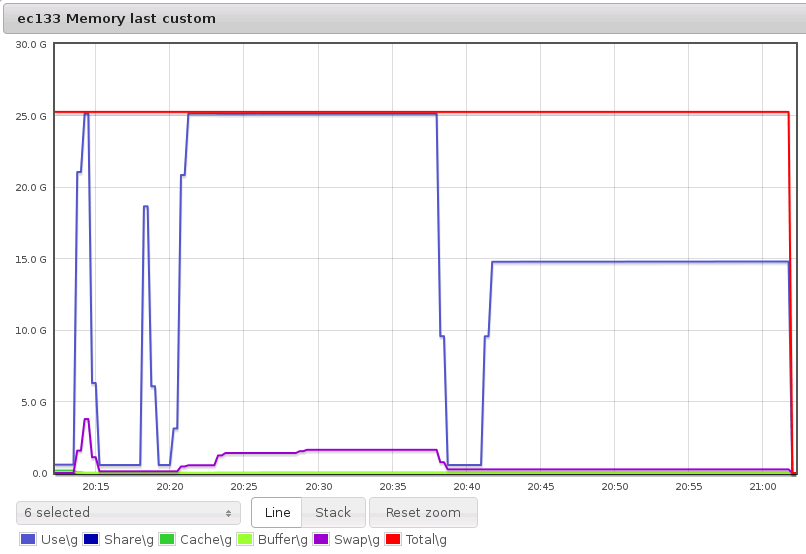
After rebooting the node, I verified that it was again able to allocate memory like it did before “thrashing.” The most likely cause of the problem is memory fragmentation, which can be assessed through /proc/buddyinfo (also see official docs for /proc/buddyinfo). Here are two representative outputs (not from the same test show above). The first one shows a freshly booted node. Note the high number of available large memory chunks in the columns towards the right:
[root@ec98 ~]# cat /proc/buddyinfo Node 0, zone DMA 3 2 4 3 2 2 0 0 2 0 2 Node 0, zone DMA32 0 0 1 0 4 3 5 3 4 6 472 Node 0, zone Normal 180 51 37 23 11 11 8 6 2 1 2831 Node 1, zone Normal 354 192 40 29 121 43 3 1 1 0 4026
Now, let’s look at the node after it has been thrashing. Note that the number of small chunks in the left columns has greatly increased, while the number of large chunks has gone down significantly:
[root@ec98 ~]# cat /proc/buddyinfo Node 0, zone DMA 3 2 4 3 2 2 0 0 2 0 2 Node 0, zone DMA32 589 390 332 369 370 362 356 350 345 61 269 Node 0, zone Normal 5840 10942 9578 8469 7558 6531 5297 3617 1964 612 1363 Node 1, zone Normal 1925 3069 2674 2447 2238 2066 1896 1648 1157 700 2931
This data demonstrates that a node which has “thrashed” is no longer capable of allocating large blocks of RAM. This phenomenon can cause a significant problem for a high-performance computing cluster in which users are allowed to execute programs on “bare metal” compute nodes. One user can “thrash” a node and kill the job, leaving the node in a “soft failure” state which cannot be detected by any standard monitoring tools. The next user will make a reasonable RAM request but the job will “hang” while the node thrashes, wasting their compute time. In a future post, I will evaluate options for preventing this problem.